My name is Alex Turner. I'm a research scientist at Google DeepMind on the Scalable Alignment team. My views are strictly my own; I do not represent Google. Reach me at alex[at]turntrout.com
Posts
Wiki Contributions
Comments
When we then run the model on harmless prompts, we intervene such that the expression of the "refusal direction" is set to the average expression on harmful prompts:
Note that the average projection measurement and the intervention are performed only at layer , the layer at which the best "refusal direction" was extracted from.
Was it substantially less effective to instead use
?
We find this result unsurprising and implied by prior work, but include it for completeness. For example, Zou et al. 2023 showed that adding a harmfulness direction led to an 8 percentage point increase in refusal on harmless prompts in Vicuna 13B.
I do want to note that your boost in refusals seems absolutely huge, well beyond 8%? I am somewhat surprised by how huge your boost is.
using this direction to intervene on model activations to steer the model towards or away from the concept (Burns et al. 2022
Burns et al. do activation engineering? I thought the CCS paper didn't involve that.
Because fine-tuning can be a pain and expensive? But you can probably do this quite quickly and painlessly.
If you want to say finetuning is better than this, or (more relevantly) finetuning + this, can you provide some evidence?
I would definitely like to see quantification of the degree to which MELBO elicits natural, preexisting behaviors. One challenge in the literature is: you might hope to see if a network "knows" a fact by optimizing a prompt input to produce that fact as an output. However, even randomly initialized networks can be made to output those facts, so "just optimize an embedded prompt using gradient descent" is too expressive.
One of my hopes here is that the large majority of the steered behaviors are in fact natural. One reason for hope is that we aren't optimizing to any behavior in particular, we just optimize for L2 distance and the behavior is a side effect. Furthermore, MELBO finding the backdoored behaviors (which we literally taught the model to do in narrow situations) is positive evidence.
If MELBO does elicit natural behaviors (as I suspect it does), that would be quite useful for training, eval, and red-teaming purposes.
A semi-formalization of shard theory. I think that there is a surprisingly deep link between "the AIs which can be manipulated using steering vectors" and "policies which are made of shards."[1] In particular, here is a candidate definition of a shard theoretic policy:
A policy has shards if it implements at least two "motivational circuits" (shards) which can independently activate (more precisely, the shard activation contexts are compositionally represented).
By this definition, humans have shards because they can want food at the same time as wanting to see their parents again, and both factors can affect their planning at the same time! The maze-solving policy is made of shards because we found activation directions for two motivational circuits (the cheese direction, and the top-right direction):
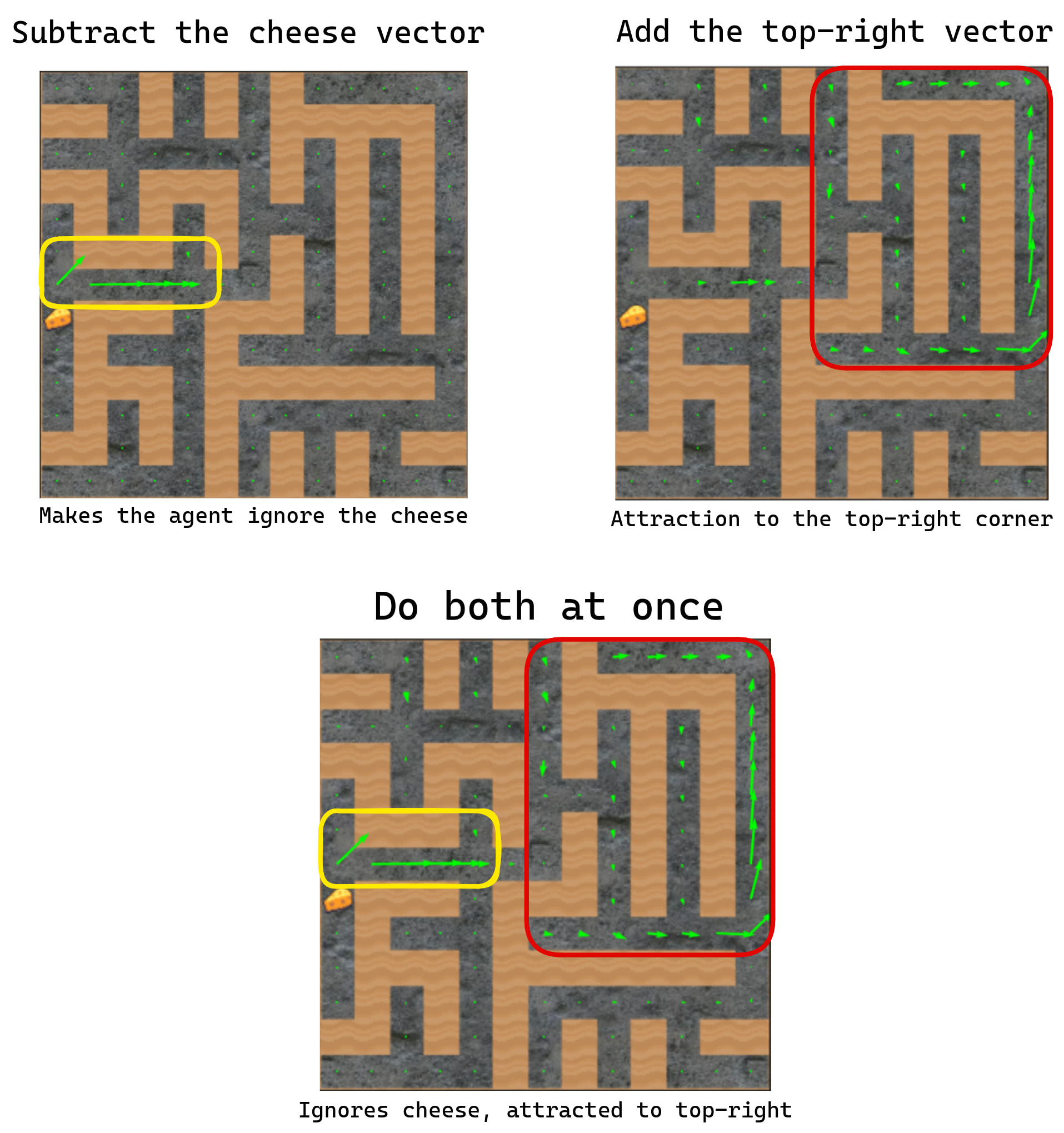
On the other hand, AIXI is not a shard theoretic agent because it does not have two motivational circuits which can be activated independently of each other. It's just maximizing one utility function. A mesa optimizer with a single goal also does not have two motivational circuits which can go on and off in an independent fashion.
- This definition also makes obvious the fact that "shards" are a matter of implementation, not of behavior.
- It also captures the fact that "shard" definitions are somewhat subjective. In one moment, I might model someone is having a separate "ice cream shard" and "cookie shard", but in another situation I might choose to model those two circuits as a larger "sweet food shard."
So I think this captures something important. However, it leaves a few things to be desired:
- What, exactly, is a "motivational circuit"? Obvious definitions seem to include every neural network with nonconstant outputs.
- Demanding a compositional representation is unrealistic since it ignores superposition. If dimensions are compositional, then they must be pairwise orthogonal. Then a transformer can only have shards, which seems obviously wrong and false.
That said, I still find this definition useful.
I came up with this last summer, but never got around to posting it. Hopefully this is better than nothing.
- ^
Shard theory reasoning led me to discover the steering vector technique extremely quickly. This link would explain why shard theory might help discover such a technique.
the hope is that by "nudging" the model at an early layer, we can activate one of the many latent behaviors residing within the LLM.
In the language of shard theory: "the hope is that shards activate based on feature directions in early layers. By adding in these directions, the corresponding shards activate different behaviors in the model."
It's a good experiment to run, but the answer is "no, the results are not similar." From the post (the first bit of emphasis added):
I hypothesize that the reason why the method works is due to the noise-stability of deep nets. In particular, my subjective impression (from experiments) is that for random steering vectors, there is no Goldilocks value of which leads to meaningfully different continuations. In fact, if we take random vectors with the same radius as "interesting" learned steering vectors, the random vectors typically lead to uninteresting re-phrasings of the model's unsteered continuation, if they even lead to any changes (a fact previously observed by Turner et al. (2023))[7][8]. Thus, in some sense, learned vectors (or more generally, adapters) at the Golidlocks value of are very special; the fact that they lead to any downstream changes at all is evidence that they place significant weight on structurally important directions in activation space[9].
I'm really excited about Andrew's discovery here. With it, maybe we can get a more complete picture of what these models can do, and how. This feels like the most promising new idea I've seen in a while. I expect it to open up a few new affordances and research directions. Time will tell how reliable and scalable this technique is. I sure hope this technique gets the attention and investigation it (IMO) deserves.
More technically, his discovery unlocks the possibility of unsupervised capability elicitation, whereby we can automatically discover a subset of "nearby" abilities and behavioral "modes", without the intervention itself "teaching" the model the elicited ability or information.
As Turntrout has already noted, that does not apply to model-based algorithms, and they 'do optimize the reward':
I think that you still haven't quite grasped what I was saying. Reward is not the optimization target totally applies here. (It was the post itself which only analyzed the model-free case, not that the lesson only applies to the model-free case.)
In the partial quote you provided, I was discussing two specific algorithms which are highly dissimilar to those being discussed here. If (as we were discussing), you're doing MCTS (or "full-blown backwards induction") on reward for the leaf nodes, the system optimizes the reward. That is -- if most of the optimization power comes from explicit search on an explicit reward criterion (as in AIXI), then you're optimizing for reward. If you're doing e.g. AlphaZero, that aggregate system isn't optimizing for reward.
Despite the derision which accompanies your discussion of Reward is not the optimization target, it seems to me that you still do not understand the points I'm trying to communicate. You should be aware that I don't think you understand my views or that post's intended lesson. As I offered before, I'd be open to discussing this more at length if you want clarification.
CC @faul_sname
Nope! I have basically always enjoyed talking with you, even when we disagree.
If that were true, I'd expect the reactions to a subsequent LLAMA3 weight orthogonalization jailbreak to be more like "yawn we already have better stuff" and not "oh cool, this is quite effective!" Seems to me from reception that this is letting people either do new things or do it faster, but maybe you have a concrete counter-consideration here?