Well I’m one of the people who says that “AGI” is the scary thing that doesn’t exist yet (e.g. FAQ or “why I want to move the goalposts on ‘AGI’”). I don’t think “AGI” is a perfect term for the scary thing that doesn’t exist yet, but my current take is that “AGI” is a less bad term compared to alternatives. (I was listing out some other options here.) In particular, I don’t think there’s any terminological option that is sufficiently widely-understood and unambiguous that I wouldn’t need to include a footnote or link explaining exactly what I mean. And if I’m going to do that anyway, doing that with “AGI” seems OK. But I’m open-minded to discussing other options if you (or anyone) have any.
Generative pre-training is AGI technology: it creates a model with mediocre competence at basically everything.
I disagree with that—as in “why I want to move the goalposts on ‘AGI’”, I think there’s an especially important category of capability that entails spending a whole lot of time working with a system / idea / domain, and getting to know it and understand it and manipulate it better and better over the course of time. Mathematicians do this with abstruse mathematical objects, but also trainee accountants do this with spreadsheets, and trainee car mechanics do this with car engines and pliers, and kids do this with toys, and gymnasts do this with their own bodies, etc. I propose that LLMs cannot do things in this category at human level, as of today—e.g. AutoGPT basically doesn’t work, last I heard. And this category of capability isn’t just a random cherrypicked task, but rather central to human capabilities, I claim. (See Section 3.1 here.)
Thanks for your perspective! I think explicitly moving the goal-posts is a reasonable thing to do here, although I would prefer to do this in a way that doesn't harm the meaning of existing terms.
I mean: I think a lot of people did have some kind of internal "human-level AGI" goalpost which they imagined in a specific way, and modern AI development has resulted in a thing which fits part of that image while not fitting other parts, and it makes a lot of sense to reassess things. Goalpost-moving is usually maligned as an error, but sometimes it actually makes sense.
I prefer 'transformative AI' for the scary thing that isn't here yet. I see where you're coming from with respect to not wanting to have to explain a new term, but I think 'AGI' is probably still more obscure for a general audience than you think it is (see, eg, the snarky complaint here). Of course it depends on your target audience. But 'transformative AI' seems relatively self-explanatory as these things go. I see that you have even used that term at times.
I disagree with that—as in “why I want to move the goalposts on ‘AGI’”, I think there’s an especially important category of capability that entails spending a whole lot of time working with a system / idea / domain, and getting to know it and understand it and manipulate it better and better over the course of time. Mathematicians do this with abstruse mathematical objects, but also trainee accountants do this with spreadsheets, and trainee car mechanics do this with car engines and pliers, and kids do this with toys, and gymnasts do this with their own bodies, etc. I propose that LLMs cannot do things in this category at human level, as of today—e.g. AutoGPT basically doesn’t work, last I heard. And this category of capability isn’t just a random cherrypicked task, but rather central to human capabilities, I claim. (See Section 3.1 here.)
I do think this is gesturing at something important. This feels very similar to the sort of pushback I've gotten from other people. Something like: "the fact that AIs can perform well on most easily-measured tasks doesn't tell us that AIs are on the same level as humans; it tells us that easily-measured tasks are less informative about intelligence than we thought".
Currently I think LLMs have a small amount of this thing, rather than zero. But my picture of it remains fuzzy.
My complaint about “transformative AI” is that (IIUC) its original and universal definition is not about what the algorithm can do but rather how it impacts the world, which is a different topic. For example, the very same algorithm might be TAI if it costs $1/hour but not TAI if it costs $1B/hour, or TAI if it runs at a certain speed but not TAI if it runs many OOM slower, or “not TAI because it’s illegal”. Also, two people can agree about what an algorithm can do but disagree about what its consequences would be on the world, e.g. here’s a blog post claiming that if we have cheap AIs that can do literally everything that a human can do, the result would be “a pluralistic and competitive economy that’s not too different from the one we have now”, which I view as patently absurd.
Anyway, “how an AI algorithm impacts the world” is obviously an important thing to talk about, but “what an AI algorithm can do” is also an important topic, and different, and that’s what I’m asking about, and “TAI” doesn’t seem to fit it as terminology.
Yep, I agree that Transformative AI is about impact on the world rather than capabilities of the system. I think that is the right thing to talk about for things like "AI timelines" if the discussion is mainly about the future of humanity. But, yeah, definitely not always what you want to talk about.
I am having difficulty coming up with a term which points at what you want to point at, so yeah, I see the problem.
I agree with Steve Byrnes here. I think I have a better way to describe this.
I would say that the missing piece is 'mastery'. Specifically, learning mastery over a piece of reality. By mastery I am referring to the skillful ability to model, predict, and purposefully manipulate that subset of reality.
I don't think this is an algorithmic limitation, exactly.
Look at the work Deepmind has been doing, particularly with Gato and more recently AutoRT, SARA-RT, RT-Trajectory, UniSim , and Q-transformer. Look at the work being done with the help of Nvidia's new Robot Simulation Gym Environment. Look at OpenAI's recent foray into robotics with Figure AI. This work is held back from being highly impactful (so far) by the difficulty of accurately simulating novel interesting things, the difficulty of learning the pairing of action -> consequence compared to learning a static pattern of data, and the hardware difficulties of robotics.
This is what I think our current multimodal frontier models are mostly lacking. They can regurgitate, and to a lesser extent synthesize, facts that humans wrote about, but not develop novel mastery of subjects and then report back on their findings. This is the difference between being able to write a good scientific paper given a dataset of experimental results and rough description of the experiment, versus being able to gather that data yourself. The line here is blurry, and will probably get blurrier before collapsing entirely. It's about not just doing the experiment, but doing the pilot studies and observations and playing around with the parameters to build a crude initial model about how this particular piece of the universe might work. Building your own new models rather than absorbing models built by others. Moving beyond student to scientist.
This is in large part a limitation of training expense. It's difficult to have enough on-topic information available in parallel to feed the data-inefficient current algorithms many lifetimes-worth of experience.
So, while it is possible to improve the skill of mastery-of-reality with scaling up current models and training systems, it gets much much easier if the algorithms get more compute-efficient and data-sample-efficient to train.
That is what I think is coming.
I've done my own in-depth research into the state of the field of machine learning and potential novel algorithmic advances which have not yet been incorporated into frontier models, and in-depth research into the state of neuroscience's understanding of the brain. I have written a report detailing the ways in which I think Joe Carlsmith's and Ajeya Cotra's estimates are overestimating the AGI-relevant compute of the human brain by somewhere between 10x to 100x.
Furthermore, I think that there are compelling arguments for why the compute in frontier algorithms is not being deployed as efficiently as it could be, resulting in higher training costs and data requirements than is theoretically possible.
In combination, these findings lead me to believe we are primarily algorithm-constrained not hardware or data constrained. Which, in turn, means that once frontier models have progressed to the point of being able to automate research for improved algorithms I expect that substantial progress will follow. This progress will, if I am correct, be untethered to further increases in compute hardware or training data.
My best guess is that a frontier model of the approximate expected capability of GPT-5 or GPT-6 (equivalently Claude 4 or 5, or similar advances in Gemini) will be sufficient for the automation of algorithmic exploration to an extent that the necessary algorithmic breakthroughs will be made. I don't expect the search process to take more than a year. So I think we should expect a time of algorithmic discovery in the next 2 - 3 years which leads to a strong increase in AGI capabilities even holding compute and data constant.
I expect that 'mastery of novel pieces of reality' will continue to lag behind ability to regurgitate and recombine recorded knowledge. Indeed, recombining information clearly seems to be lagging behind regurgitation or creative extrapolation. Not as far behind as mastery, so in some middle range.
If you imagine the whole skillset remaining in its relative configuration of peaks and valleys, but shifted upwards such that the currently lagging 'mastery' skill is at human level and a lot of other skills are well beyond, then you will be picturing something similar to what I am picturing.
[Edit:
This is what I mean when I say it isn't a limit of the algorithm per say. Change the framing of the data, and you change the distribution of the outputs.
]
I propose that LLMs cannot do things in this category at human level, as of today—e.g. AutoGPT basically doesn’t work, last I heard. And this category of capability isn’t just a random cherrypicked task, but rather central to human capabilities, I claim.
What would you claim is a central example of a task which requires this type of learning? ARA type tasks? Agency tasks? Novel ML research? Do you think these tasks certainly require something qualitatively different than a scaled up version of what we have now (pretraining, in-context learning, RL, maybe training on synthetic domain specific datasets)? If so, why? (Feel free to not answer this or just link me what you've written on the topic. I'm more just reacting than making a bid for you to answer these questions here.)
Separately, I think it's non-obvious that you can't make human-competitive sample efficient learning happen in many domains where LLMs are already competitive with humans in other non-learning ways by spending massive amounts of compute doing training (with SGD) and synthetic data generation. (See e.g. efficient-zero.) It's just that the amount of compute/spend is such that you're just effectively doing a bunch more pretraining and thus it's not really an interestingly different concept. (See also the discussion here which is mildly relevant.)
In domains where LLMs are much worse than typical humans in non-learning ways, it's harder to do the comparison, but it's still non-obvious that the learning speed is worse given massive computational resources and some investment.
I’m talking about the AI’s ability to learn / figure out a new system / idea / domain on the fly. It’s hard to point to a particular “task” that specifically tests this ability (in the way that people normally use the term “task”), because for any possible task, maybe the AI happens to already know how to do it.
You could filter the training data, but doing that in practice might be kinda tricky because “the AI already knows how to do X” is distinct from “the AI has already seen examples of X in the training data”. LLMs “already know how to do” lots of things that are not superficially in the training data, just as humans “already know how to do” lots of things that are superficially unlike anything they’ve seen before—e.g. I can ask a random human to imagine a purple colander falling out of an airplane and answer simple questions about it, and they’ll do it skillfully and instantaneously. That’s the inference algorithm, not the learning algorithm.
Well, getting an AI to invent a new scientific field would work as such a task, because it’s not in the training data by definition. But that’s such a high bar as to be unhelpful in practice. Maybe tasks that we think of as more suited to RL, like low-level robot control, or skillfully playing games that aren’t like anything in the training data?
Separately, I think there are lots of domains where “just generate synthetic data” is not a thing you can do. If an AI doesn’t fully ‘understand’ the physics concept of “superradiance” based on all existing human writing, how would it generate synthetic data to get better? If an AI is making errors in its analysis of the tax code, how would it generate synthetic data to get better? (If you or anyone has a good answer to those questions, maybe you shouldn’t publish them!! :-P )
Yes, this is almost exactly it. I don't expect frontier LLMs to carry out a complicated, multi-step process and recover from obstacles.
I think of this as the "squirrel bird feeder test". Squirrels are ingenious and persistent problem solvers, capable of overcoming chains of complex obstacles. LLMs really can't do this (though Devin is getting closer, if demos are to be believed).
Here's a simple test: Ask an AI to open and manage a local pizza restaurant, buying kitchen equipment, dealing with contractors, selecting recipes, hiring human employees to serve or clean, registering the business, handling inspections, paying taxes, etc. None of these are expert-level skills. But frontier models are missing several key abilities. So I do not consider them AGI.
However, I agree that LLMs already have superhuman language skills in many areas. They have many, many parts of what's needed to complete challenges like the above. (On principle, I won't try to list what I think they're missing.)
I fear the period between "actual AGI and weak ASI" will be extremely short. And I don't actually believe there is any long-term way to control ASI.
I fear that most futures lead to a partially-aligned super-human intelligence with its own goals. And any actual control we have will be transitory.
Here's a simple test: Ask an AI to open and manage a local pizza restaurant, buying kitchen equipment, dealing with contractors, selecting recipes, hiring human employees to serve or clean, registering the business, handling inspections, paying taxes, etc. None of these are expert-level skills. But frontier models are missing several key abilities. So I do not consider them AGI.
I agree that this is a thing current AI systems don't/can't do, and that aren't considered expert-level skills for humans. I disagree that this is a simple test, or the kind of thing a typical human can do without lots of feedback, failures, or assistance. Many very smart humans fail at some or all of these tasks. They give up on starting a business, mess up their taxes, have a hard time navigating bureaucratic red tape, and don't ever learn to cook. I agree that if an AI could do these things it would be much harder to argue against it being AGI, but it's important to remember that many healthy, intelligent, adult humans can't, at least not reliably. Also, remember that most restaurants fail within a couple of years even after making it through all these hoops. The rate is very high even for experienced restauranteurs doing the managing.
I suppose you could argue for a definition of general intelligence that excludes a substantial fraction of humans, but for many reasons I wouldn't recommend it.
Yeah, the precise ability I'm trying to point to here is tricky. Almost any human (barring certain forms of senility, severe disability, etc) can do some version of what I'm talking about. But as in the restaurant example, not every human could succeed at every possible example.
I was trying to better describe the abilities that I thought GPT-4 was lacking, using very simple examples. And it started looking way too much like a benchmark suite that people could target.
Suffice to say, I don't think GPT-4 is an AGI. But I strongly suspect we're only a couple of breakthroughs away. And if anyone builds an AGI, I am not optimistic we will remain in control of our futures.
I agree the term AGI is rough and might be more misleading than it's worth in some cases. But I do quite strongly disagree that current models are 'AGI' in the sense most people intend.
Examples of very important areas where 'average humans' plausibly do way better than current transformers:
- Most humans succeed in making money autonomously. Even if they might not come up with a great idea to quickly 10x $100 through entrepreneurship, they are able to find and execute jobs that people are willing to pay a lot of money for. And many of these jobs are digital and could in theory be done just as well by AIs. Certainly there is a ton of infrastructure built up around humans that help them accomplish this which doesn't really exist for AI systems yet, but if this situation was somehow equalized I would very strongly bet on the average human doing better than the average GPT-4-based agent. It seems clear to me that humans are just way more resourceful, agentic, able to learn and adapt etc. than current transformers are in key ways.
- Many humans currently do drastically better on the METR task suite (https://github.com/METR/public-tasks) than any AI agents, and I think this captures some important missing capabilities that I would expect an 'AGI' system to possess. This is complicated somewhat by the human subjects not being 'average' in many ways, e.g. we've mostly tried this with US tech professionals and the tasks include a lot of SWE, so most people would likely fail due to lack of coding experience.
- Take enough randomly sampled humans and set them up with the right incentives and they will form societies, invent incredibly technologies, build productive companies etc. whereas I don't think you'll get anything close to this with a bunch of GPT-4 copies at the moment
I think AGI for most people evokes something that would do as well as humans on real-world things like the above, not just something that does as well as humans on standardized tests.
Current AIs suck at agency skills. Put a bunch of them in AutoGPT scaffolds and give them each their own computer and access to the internet and contact info for each other and let them run autonomously for weeks and... well I'm curious to find out what will happen, I expect it to be entertaining but not impressive or useful. Whereas, as you say, randomly sampled humans would form societies and fnd jobs etc.
This is the common thread behind all your examples Hjalmar. Once we teach our AIs agency (i.e. once they have lots of training-experience operating autonomously in pursuit of goals in sufficiently diverse/challenging environments that they generalize rather than overfit to their environment) then they'll be AGI imo. And also takeoff will begin, takeover will become a real possibility, etc. Off to the races.
Yeah, I agree that lack of agency skills are an important part of the remaining human<>AI gap, and that it's possible that this won't be too difficult to solve (and that this could then lead to rapid further recursive improvements). I was just pointing toward evidence that there is a gap at the moment, and that current systems are poorly described as AGI.
With respect to METR, yeah, this feels like it falls under my argument against comparing performance against human experts when assessing whether AI is "human-level". This is not to deny the claim that these tasks may shine a light on fundamentally missing capabilities; as I said, I am not claiming that modern AI is within human range on all human capabilities, only enough that I think "human level" is a sensible label to apply.
However, the point about autonomously making money feels more hard-hitting, and has been repeated by a few other commenters. I can at least concede that this is a very sensible definition of AGI, which pretty clearly has not yet been satisfied. Possibly I should reconsider my position further.
The point about forming societies seems less clear. Productive labor in the current economy is in some ways much more complex and harder to navigate than it would be in a new society built from scratch. The Generative Agents paper gives some evidence in favor of LLM-base agents coordinating social events.
I think humans doing METR's tasks are more like "expert-level" rather than average/"human-level". But current LLM agents are also far below human performance on tasks that don't require any special expertise.
From GAIA:
GAIA proposes real-world questions that require a set of fundamental abilities such as reasoning, multi-modality handling, web browsing, and generally tool-use proficiency. GAIA questions are conceptually simple for humans yet challenging for most advanced AIs: we show that human respondents obtain 92% vs. 15% for GPT-4 equipped with plugins. [Note: The latest highest AI agent score is now 39%.] This notable performance disparity contrasts with the recent trend of LLMs outperforming humans on tasks requiring professional skills in e.g. law or chemistry. GAIA's philosophy departs from the current trend in AI benchmarks suggesting to target tasks that are ever more difficult for humans. We posit that the advent of Artificial General Intelligence (AGI) hinges on a system's capability to exhibit similar robustness as the average human does on such questions.
And LLMs and VLLMs seriously underperform humans in VisualWebArena, which tests for simple web-browsing capabilities:
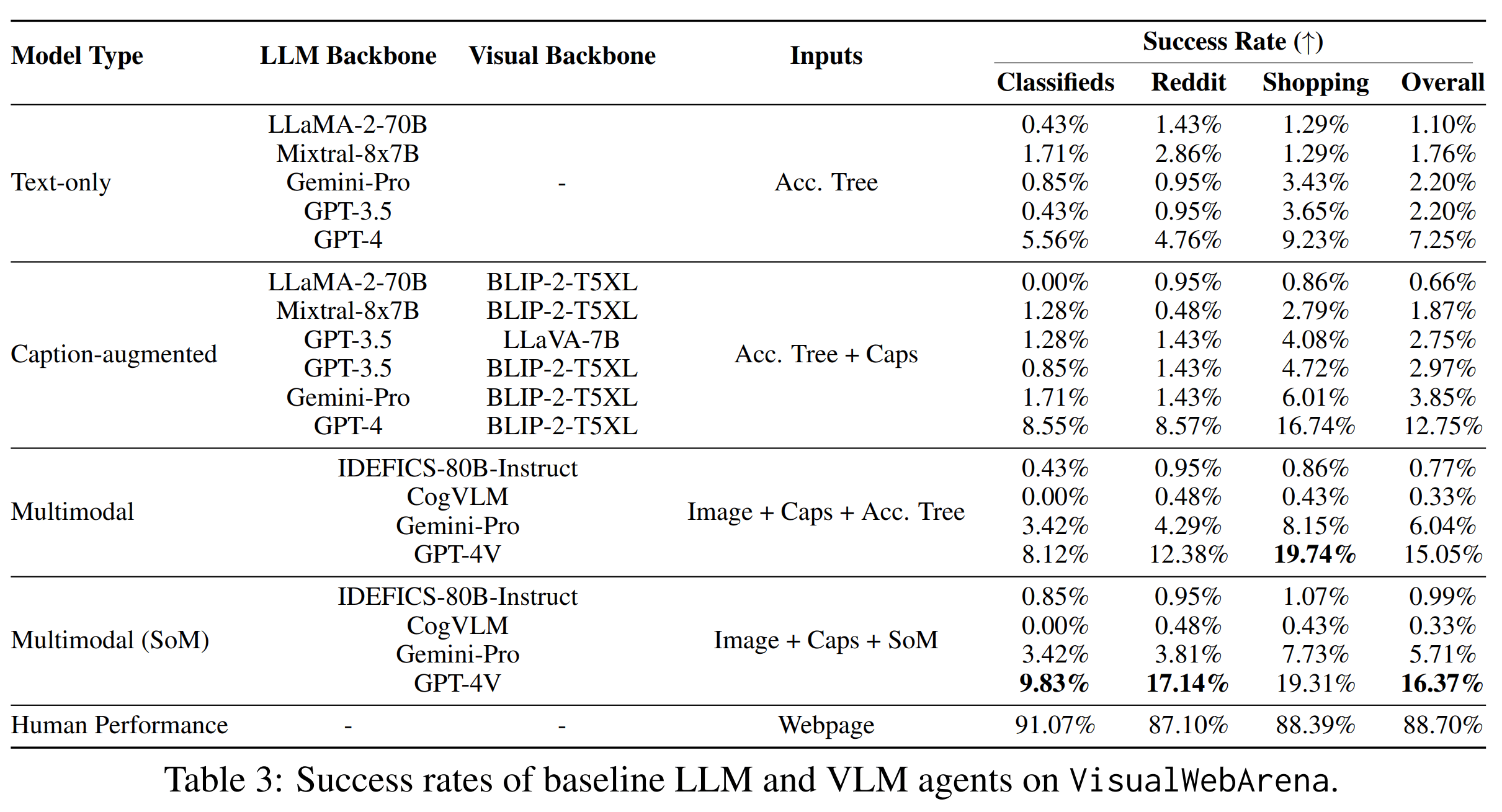

I don't know if being able to autonomously make money should be a necessary condition to qualify as AGI. But I would feel uncomfortable calling a system AGI if it can't match human performance at simple agent tasks.
However, the point about autonomously making money feels more hard-hitting, and has been repeated by a few other commenters. I can at least concede that this is a very sensible definition of AGI, which pretty clearly has not yet been satisfied. Possibly I should reconsider my position further.
This is what jumped out at me when I read your post. Transformer LLM can be described as a "disabled human who is blind to motion and needs seconds to see a still image, paralyzed, costs expensive resources to live, cannot learn, and has no long term memory". Oh and they finished high school and some college across all majors.
"What job can they do and how much will you pay". "Can they support themselves financially?".
And you end up with "well for most of human history, a human with those disabilities would be a net drain on their tribe. Sometimes they were abandoned to die as a consequence. "
And it implies something like "can perform robot manipulation and wash dishes, or the "make a cup of coffee in a strangers house" test. And reliably enough to be paid minimum wage or at least some money under the table to do a task like this.
We really could be 3-5 years from that, if all you need for AGI is "video perception, online learning, long term memory, and 5-25th percentile human like robotics control". 3/4 elements exist in someone's lab right now, the robotics control maybe not.
This "economic viability test" has an interesting followup question. It's possible for a human to remain alive and living in a car or tent under a bridge for a few dollars an hour. This is the "minimum income to survive" for a human. But a robotic system may blow a $10,000 part every 1000 hours, or need $100 an hour of rented B200 compute to think with.
So the minimum hourly rate could be higher. I think maybe we should use the human dollar figures for this "can survive" level of AGI capabilities test, since robotic and compute costs are so easy and fast to optimize.
Summary :
AGI when the AI systems can do a variety of general tasks, completely, you would pay a human employee to do, even a low end one.
Transformative AGI (one of many thresholds) when the AI system can do a task and be paid more than the hourly cost of compute + robotic hourly costs.
Note "transformation" is reached when the lowest threshold is reached. Noticed that error all over, lots of people like Daniel and Richard have thresholds where AI will definitely be transformational, such as "can autonomously perform ai research" but don't seem to think "can wash dishes or sort garbage and produce more value than operating cost" is transformational.
Those events could be decades apart.
And you end up with "well for most of human history, a human with those disabilities would be a net drain on their tribe. Sometimes they were abandoned to die as a consequence. "
And it implies something like "can perform robot manipulation and wash dishes, or the "make a cup of coffee in a strangers house" test. And reliably enough to be paid minimum wage or at least some money under the table to do a task like this.
The replace-human-labor test gets quite interesting and complex when we start to time-index it. Specifically, two time-indexes are needed: a 'baseline' time (when humans are doing all the relevant work) and a comparison time (where we check how much of the baseline economy has been automated).
Without looking anything up, I guess we could say that machines have already automated 90% of the economy, if we choose our baseline from somewhere before industrial farming equipment, and our comparison time somewhere after. But this is obviously not AGI.
A human who can do exactly what GPT4 can do is not economically viable in 2024, but might have been economically viable in 2020.
I'm saying "transformers" every time I am tempted to write "LLMs" because many modern LLMs also do image processing, so the term "LLM" is not quite right.
"Transformer"'s not quite right either because you can train a transformer on a narrow task. How about foundation model: "models (e.g., BERT, DALL-E, GPT-3) that are trained on broad data at scale and are adaptable to a wide range of downstream tasks".
I agree 100%. It would be interesting to explore how the term "AGI" has evolved, maybe starting with Goertzel and Pennachin 2007 who define it as:
a software program that can solve a variety of complex problems in a variety of different domains, and that controls itself autonomously, with its own thoughts, worries, feelings, strengths, weaknesses and predispositions
On the other hand, Stuart Russell testified that AGI means
machines that match or exceed human capabilities in every relevant dimension
so the experts seem to disagree. (On the other hand, Stuart & Russell's textbook cite Goertzel and Pennachin 2007 when mentioning AGI. Confusing.)
In any case, I think it's right to say that today's best language models are AGIs for any of these reasons:
- They're not narrow AIs.
- They satisfy the important parts of Goertzel and Pennachin's definition.
- The tasks they can perform are not limited to a "bounded" domain.
In fact, GPT-2 is an AGI.
I agree with virtually all of the high-level points in this post — the term "AGI" did not seem to usually initially refer to a system that was better than all human experts at absolutely everything, transformers are not a narrow technology, and current frontier models can meaningfully be called "AGI".
Indeed, my own attempt to define AGI a few years ago was initially criticized for being too strong, as I initially specified a difficult construction task, which was later weakened to being able to "satisfactorily assemble a (or the equivalent of a) circa-2021 Ferrari 312 T4 1:8 scale automobile model" in response to pushback. These days the opposite criticism is generally given: that my definition is too weak.
However, I do think there is a meaningful sense in which current frontier AIs are not "AGI" in a way that does not require goalpost shifting. Various economically-minded people have provided definitions for AGI that were essentially "can the system perform most human jobs?" And as far as I can tell, this definition has held up remarkably well.
For example, Tobias Baumann wrote in 2018,
A commonly used reference point is the attainment of “human-level” general intelligence (also called AGI, artificial general intelligence), which is defined as the ability to successfully perform any intellectual task that a human is capable of. The reference point for the end of the transition is the attainment of superintelligence – being vastly superior to humans at any intellectual task – and the “decisive strategic advantage” (DSA) that ensues.1 The question, then, is how long it takes to get from human-level intelligence to superintelligence.
I find this definition problematic. The framing suggests that there will be a point in time when machine intelligence can meaningfully be called “human-level”. But I expect artificial intelligence to differ radically from human intelligence in many ways. In particular, the distribution of strengths and weaknesses over different domains or different types of reasoning is and will likely be different2 – just as machines are currently superhuman at chess and Go, but tend to lack “common sense”. AI systems may also diverge from biological minds in terms of speed, communication bandwidth, reliability, the possibility to create arbitrary numbers of copies, and entanglement with existing systems.
Unless we have reason to expect a much higher degree of convergence between human and artificial intelligence in the future, this implies that at the point where AI systems are at least on par with humans at any intellectual task, they actually vastly surpass humans in most domains (and have just fixed their worst weakness). So, in this view, “human-level AI” marks the end of the transition to powerful AI rather than its beginning.
As an alternative, I suggest that we consider the fraction of global economic activity that can be attributed to (autonomous) AI systems.3 Now, we can use reference points of the form “AI systems contribute X% of the global economy”. (We could also look at the fraction of resources that’s controlled by AI, but I think this is sufficiently similar to collapse both into a single dimension. There’s always a tradeoff between precision and simplicity in how we think about AI scenarios.)
Obvious bait is obvious bait, but here goes.
Transformers are not AGI because they will never be able to "figure something out" the way humans can.
If a human is given the rules for Sudoku, they first try filling in the square randomly. After a while, they notice that certain things work and certain things don't work. They begin to define heuristics for things that work (for example, if all but one number appears in the same row or column as a box, that number goes in the box). Eventually they work out a complete algorithm for solving Sudoku.
A transformer will never do this (pretending Sudoku wasn't in its training data). Because they are next-token predictors, they are fundamentally incapable of reasoning about things not in their training set. They are incapable of "noticing when they made a mistake" and then backtracking they way a human would.
Now it's entirely possible that a very small wrapper around a Transformer could solve Sudoku. You could have the transformer suggest moves and then add a reasoning/planning layer around it to handle the back-tracking. This is effectively what Alpha-Geometry does.
But a Transformer BY ITSELF will never be AGI.
Yeah, I didn't do a very good job in this respect. I am not intending to talk about a transformer by itself. I am intending to talk about transformers with the sorts of bells and whistles that they are currently being wrapped with. So not just transformers, but also not some totally speculative wrapper.
In the technical sense that you can implement arbitrary programs by prompting an LLM (they are turning complete), sure.
In a practical sense, no.
GPT-4 can't even play tic-tac-toe. Manifold spent a year getting GPT-4 to implement (much less discover) the algorithm for Sudoku and failed.
Now imagine trying to implement a serious backtracking algorithm. Stockfish checks millions of positions per turn of play. The attention window for your "backtracking transformer" is going to have to be at lease {size of chess board state}*{number of positions evaluated}.
And because of quadratic attention, training it is going to take on the order of {number or parameters}*({chess board state size}*{number of positions evaluated})^2
Even with very generous assumptions for {number of parameters} and {chess board state}, there's simply no way we could train such a model this century (and that's assuming Moore's law somehow continues that long).
The question is - how far can we get with in-context learning. If we filled Gemini's 10 million tokens with Sudoku rules and examples, showing where it went wrong each time, would it generalize? I'm not sure but I think it's possible
I agree that filling a context window with worked sudoku examples wouldn't help for solving hidouku. But, there is a common element here to the games. Both look like math, but aren't about numbers except that there's an ordered sequence. The sequence of items could just as easily be an alphabetically ordered set of words. Both are much more about geometry, or topology, or graph theory, for how a set of points is connected. I would not be surprised to learn that there is a set of tokens, containing no examples of either game, combined with a checker (like your link has) that points out when a mistake has been made, that enables solving a wide range of similar games.
I think one of the things humans do better than current LLMs is that, as we learn a new task, we vary what counts as a token and how we nest tokens. How do we chunk things? In sudoku, each box is a chunk, each row and column are a chunk, the board is a chunk, "sudoku" is a chunk, "checking an answer" is a chunk, "playing a game" is a chunk, and there are probably lots of others I'm ignoring. I don't think just prompting an LLM with the full text of "How to solve it" in its context window would get us to a solution, but at some level I do think it's possible to make explicit, in words and diagrams, what it is humans do to solve things, in a way legible to it. I think it largely resembles repeatedly telescoping in and out, to lower and higher abstractions applying different concepts and contexts, locally sanity checking ourselves, correcting locally obvious insanity, and continuing until we hit some sort of reflective consistency. Different humans have different limits on what contexts they can successfully do this in.
Absolutely. I don't think it's impossible to build such a system. In fact, I think a transformer is probably about 90% there. Need to add trial and error, some kind of long-term memory/fine-tuning and a handful of default heuristics. Scale will help too, but no amount of scale alone will get us there.
This is my personal opinion, and in particular, does not represent anything like a MIRI consensus; I've gotten push-back from almost everyone I've spoken with about this, although in most cases I believe I eventually convinced them of the narrow terminological point I'm making.
In the AI x-risk community, I think there is a tendency to ask people to estimate "time to AGI" when what is meant is really something more like "time to doom" (or, better, point-of-no-return). For about a year, I've been answering this question "zero" when asked.
This strikes some people as absurd or at best misleading. I disagree.
The term "Artificial General Intelligence" (AGI) was coined in the early 00s, to contrast with the prevalent paradigm of Narrow AI. I was getting my undergraduate computer science education in the 00s; I experienced a deeply-held conviction in my professors that the correct response to any talk of "intelligence" was "intelligence for what task?" -- to pursue intelligence in any kind of generality was unscientific, whereas trying to play chess really well or automatically detect cancer in medical scans was OK.
I think this was a reaction to the AI winter of the 1990s. The grand ambitions of the AI field, to create intelligent machines, had been discredited. Automating narrow tasks still seemed promising. "AGI" was a fringe movement.
As such, I do not think it is legitimate for the AI risk community to use the term AGI to mean 'the scary thing' -- the term AGI belongs to the AGI community, who use it specifically to contrast with narrow AI.
Modern Transformers[1] are definitely not narrow AI.
It may have still been plausible in, say, 2019. You might then have argued: "Language models are only language models! They're OK at writing, but you can't use them for anything else." It had been argued for many years that language was an AI complete task; if you can solve natural-language processing (NLP) sufficiently well, you can solve anything. However, in 2019 it might still be possible to dismiss this. Basically any narrow-AI subfield had people who will argue that that specific subfield is the best route to AGI, or the best benchmark for AGI.
The NLP people turned out to be correct. Modern NLP systems can do most things you would want an AI to do, at some basic level of competence. Critically, if you come up with a new task[2], one which the model has never been trained on, then odds are still good that it will display at least middling competence. What more could you reasonably ask for, to demonstrate 'general intelligence' rather than 'narrow'?
Generative pre-training is AGI technology: it creates a model with mediocre competence at basically everything.
Furthermore, when we measure that competence, it usually falls somewhere within the human range of performance. So, as a result, it seems sensible to call them human-level as well. It seems to me like people who protest this conclusion are engaging in goalpost-moving.
More specifically, it seems to me like complaints that modern AI systems are "dumb as rocks" are comparing AI-generated responses to human experts. A quote from the dumb-as-rocks essay:
That's a bit of a weak-man argument (I specifically searched for "generative ai is dumb as rocks what are we doing"). But it does demonstrate a pattern I've encountered. Often, the alternative to asking an AI is to ask an expert; so it becomes natural to get in the habit of comparing AI answers to expert answers. This becomes what we think about when we judge whether modern AI is "any good" -- but this is not the relevant comparison we should be using when judging whether it is "human level".
I'm certainly not claiming that modern transformers are roughly equivalent to humans in all respects. Memory works very differently for them, for example, although that has been significantly improving over the past year. One year ago I would have compared an LLM to a human with a learning disability and memory problems, but who has read the entire internet and absorbed a lot through sheer repetition. Now, those memory problems are drastically reduced.
Edited to add:
There have been many interesting comments. Two clusters of reply stick out to me:
Hjalmar Wijk would strongly bet that even if there were more infrastructure in place to help LLMs autonomously get jobs, they would be worse at this than humans. Matthew Barnett points out that economically-minded people have defined AGI in terms such as what percentage of human labor the machine is able to replace. I particularly appreciated Kaj Sotala's in-the-trenches description of trying to get GPT4 to do a job.
Kaj says GPT4 is "stupid in some very frustrating ways that a human wouldn't be" -- giving the example of GPT4 claiming that an appointment has been rescheduled, when in fact it does not even have the calendar access required to do that.
Comments on this point out that this is not an unusual customer service experience.
I do want to concede that AIs like GPT4 are quantitatively more "disconnected from reality" than humans, in an important way, which will lead them to "lie" like this more often. I also agree that GPT4 lacks the overall skills which would be required for it to make its way through the world autonomously (it would fail if it had to apply for jobs, build working relationships with humans over a long time period, rent its own server space, etc).
However, in many of these respects, it still feels comparable to the low end of human performance, rather than entirely sub-human. Autonomously making one's way through the world feels very "conjunctive" -- it requires the ability to do a lot of things right.
I never meant to claim that GPT4 is within human range on every single performance dimension; only lots and lots of them. For example, it cannot do realtime vision + motor control at anything approaching human competence (although my perspective leads me to think that this will be possible with comparable technology in the near future).
In his comment, Matthew Barnett quotes Tobias Baumann:
I think we find ourselves in a somewhat surprising future where machine intelligence actually turns out to be meaningfully "human-level" across many dimensions at once, although not all.
Anyway, the second cluster of responses I mentioned is perhaps even more interesting. Steven Byrnes has explicitly endorsed "moving the goalposts" for AGI. I do think it can sometimes be sensible to move goalposts; the concept of goalpost-moving is usually used in a negative light, but, there are times when it must be done. I wish it could be facilitated by a new term, rather than a redefinition of "AGI"; but I am not sure what to suggest.
I think there is a lot to say about Steven's notion of AGI as the-ability-to-gain-capabilities rather than as a concept of breadth-of-capability. I'll leave most of it to the comment section. To briefly respond: I agree that there is something interesting and important here. I currently think AIs like GPT4 have 'very little' of this rather than none. I also thing individual humans have very little of this. In the anthropological record, it looks like humans were not very culturally innovative for more than a hundred thousand years, until the "creative explosion" which resulted in a wide variety of tools and artistic expression. I find it plausible that this required a large population of humans to get going. Individual humans are rarely really innovative; more often, we can only introduce basic variations on existing concepts.
I'm saying "transformers" every time I am tempted to write "LLMs" because many modern LLMs also do image processing, so the term "LLM" is not quite right.
Obviously, this claim relies on some background assumption about how you come up with new tasks. Some people are skilled at critiquing modern AI by coming up with specific things which it utterly fails at. I am certainly not claiming that modern AI is literally competent at everything.
However, it does seem true to me that if you generate and grade test questions in roughly the way a teacher might, the best modern Transformers will usually fall comfortably within human range, if not better.